
Data Quality is one of the areas I have been neglecting in my home automation system so far. As a result, I seem to be capturing some ‘garbage’ data along with the good quality data. Bad data can affect downstream logic, resulting in hard to predict the behavior of the system. It is, of course, hard/costly to maintain a very high quality of data, there is a balance point that I am aiming for:
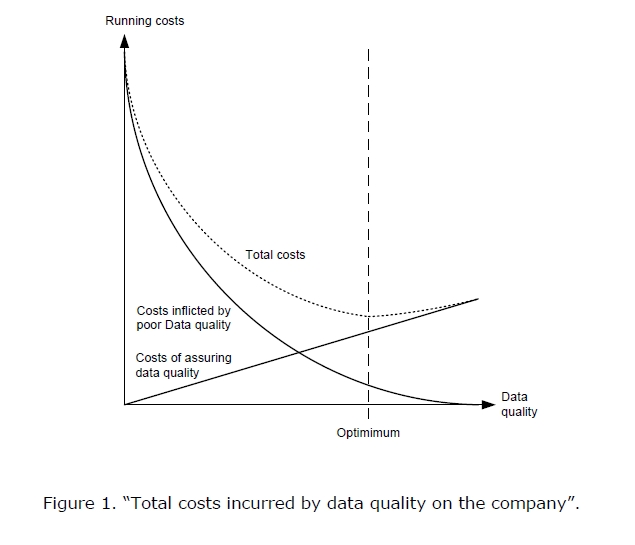
Cost of data quality
Source: http://priyamvid.blogspot.com/2012/08/the-costs-of-poor-data-quality.html
While I am running a small scale home automation system, bad data can (and is) still cause troubles; after all I rely on this data to interact with “things” from the physical and virtual worlds and some of the tasks they perform are of critical importance (hot water boiler controller, alarm system controller, fire alarm system, irrigation system, etc)
My plan is to transition from reacting to data quality failures to proactively controlling and limiting introduction of data flaws in the environment.
To achieve this, I plan to
- Profile the data
- Establish metrics
- Design and implement DQ rules
- Monitor DQ exceptions
Profile the data
This is step number one, I need to learn more about the data I am collecting, understanding the content and structure of the data will help me with the next steps. I have a number of
Physical sensors:
- Room/outdoor/heating system temperature sensors
- Humidity Sensors
- Battery Readings of sensor nodes
- Soil moisture sensor
- Power readings
- Security alarm state sensor
- Fire sensor
- Flood sensor
- Shock movement sensor
- Magnetic contact door sensors
- Bathroom scale sensor
Software data delivery bots:
- Outside freezing conditions detectors
- Presence detectors
- GPS location loggers
- Wind speed readings from remote weather stations
- Air pressure readings from remote weather stations
- Heat flux calculations
- TV/game console usage trackers
..and few more of less importance.
The assumption is that anything that can go wrong will go wrong. Given that, I need to understand what are the possible values, payload structures, the frequency of sending that each data delivery system can pass on to the home automation system for processing.
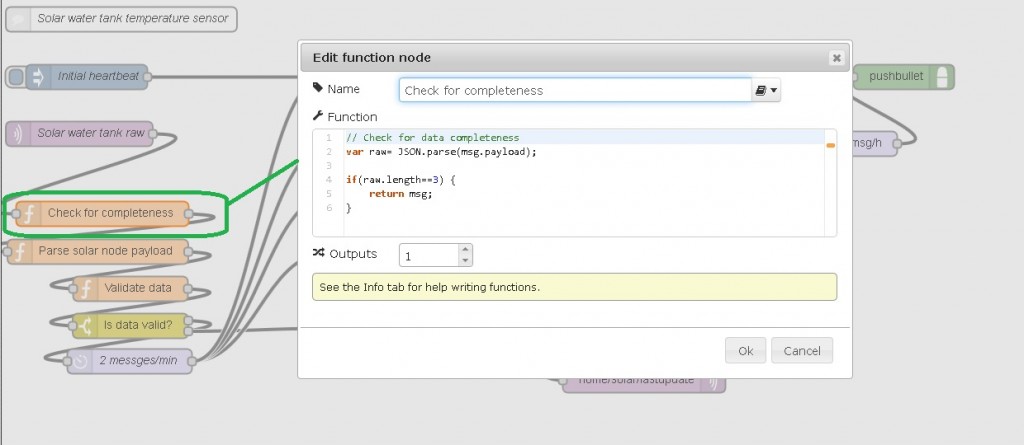
For example, room temperature reading cannot be less than -5 degrees C indoors and should not be more than 40 degrees C unless something is very, very wrong (house on fire). Hot water boiler’s temperature should vary in the range 5-99 degrees C, anything outside that range is a potential error. The DS18B20 temperature sensor I use will give a reading of 85 degrees C or 127 if it encounters an error, so I must ensure these two particular values (although possible valid reading) are not considered valid.
This sort of analysis and study of historical data provides good knowledge of the data and helps plan the next steps. It must be done for all systems that introduce data into the home automation system.
Establish metrics
The next step is to establish metrics. What Data Quality aspects do I want to monitor? What are my tolerance thresholds? The most commonly monitored DQ dimensions that are applicable to my DQ improvement efforts are:
- Completeness
- Domain Integrity
- Redundancy
- Accuracy
- Validity
- Timeliness
- Availability
Wikipedia’s entry for Data Quality says that there are over 200 such measures. The range of possible measures is only limited by the ability to provide a method for measurement.
I try to find the earliest point where bad data is generated and handle it there before it reaches other business logic.
Completeness
Completeness refers to making sure that the complete set of data makes it across data handoff points. An easy way to check if we got the complete data is to verify that the payload is of expected, pre-defined size. We know the expected payload sizes from out Data Profiling stage, so the task here is to compare the actual received payload structure/length against that expectation. The reasons for having incomplete data could be many, ranging from hardware error to human error. I observe this when by accident I use duplicate node id and send a payload of different size.
Domain Integrity
Next check that I plan to implement is to make sure that the data provided is of the correct type and fits the established in the data profiling stage allowable ranges/valid values/matches predefined pattern. This sort of DQ checks is easily performed by validating with code.
Redundancy
My next effort is to reduce the redundant data; I get redundancy mainly due to remote wireless node re-sending its payload after failing to receive ACK or as a side effect of MQTT’s QoS level 0 that can deliver one message more than once.
Accuracy
Accuracy is notoriously hard to measure, your best bet is to validate sensor’s input against another credible source. I performed a series of accuracy checks of the DHT22 temperature/air humidity sensor to check on its accuracy. Alternatively, you can check against readings from a similar sensor, for example, the outside temperature at your location cannot be +/-5 degrees from a nearby weather station.
Some sensors, like GPS, provide accuracy as part of the measurement, making the task easier. I discard inaccurate location readings, where accuracy is > 100m in my location tracking system.
Validity
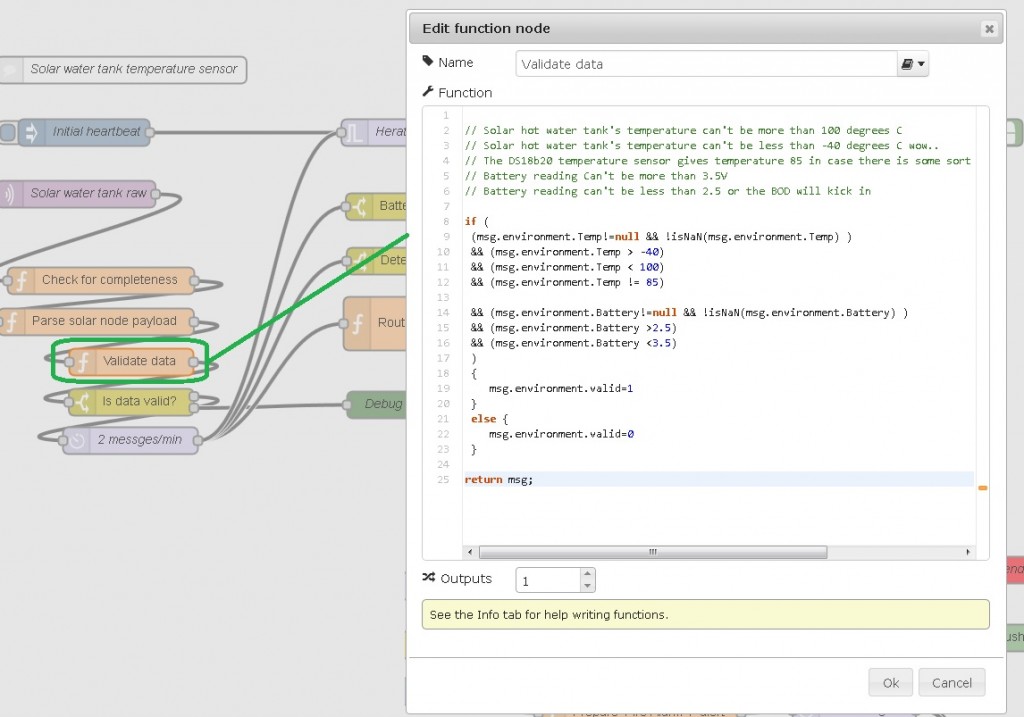
Data validity is where you make sense of the data in terms of business rules. After data has passed the domain integrity checks, it makes sense to pass it against business rule validation; Can indoor room temperature be < than -10 or > than 40 degrees C? Can hot water boiler temperature be <5 degrees C or > 99 degrees C? Can atmospheric pressure be < 900 or > 1200 where I live?
Timeliness
Timeliness is important data quality dimension when you make decisions based on data provided by other sensors. Would it make sense for the home automation system to turn on heating, if outside temperature reading is 3 days old? We need a mechanism to track the timeliness of the data and expire it based on business rules.
Availability
I have ran into a situation where a remote node has stopped sending for some reason (battery low for example), and I only find out about this days later. The availability of the data is important for decision making, so tracking that dimension and notifying me of disruptions is important.
Design and implement DQ rules
Now that I have established what aspects of Data Quality I want to measure, it is time to implement these. I have completely switched all of my business logic to Node-Red for my home automation system, so these checks will be performed there. Below is an example of my implementation of these rules for my solar hot water tank:
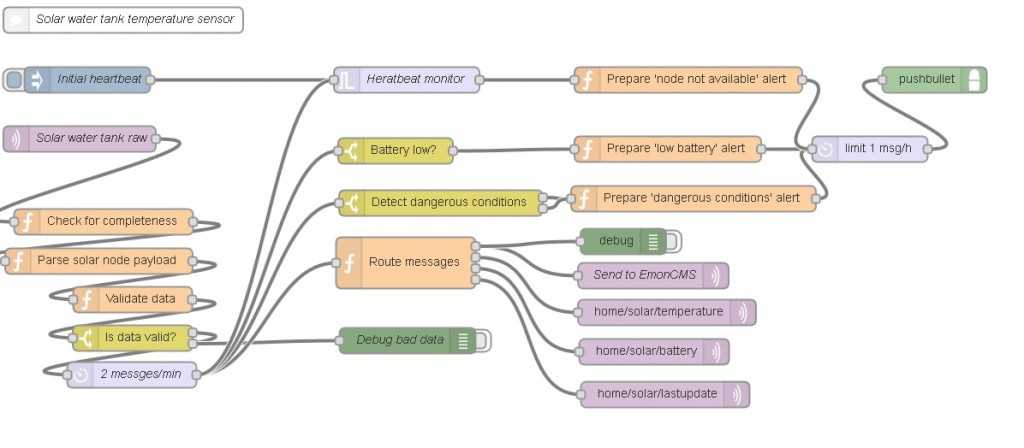
Completeness
Completeness will be ensured by simple check of payload length; should that fail, the flow does not continue:
Domain Integrity & Validity checks
I combine Domain Integrity and Validity checks in one block, probably not ideal from re-usability point of view:
Redundancy
Redundancy is handled by limiting to max of 2 messages per minute. Excessive messages are dropped:
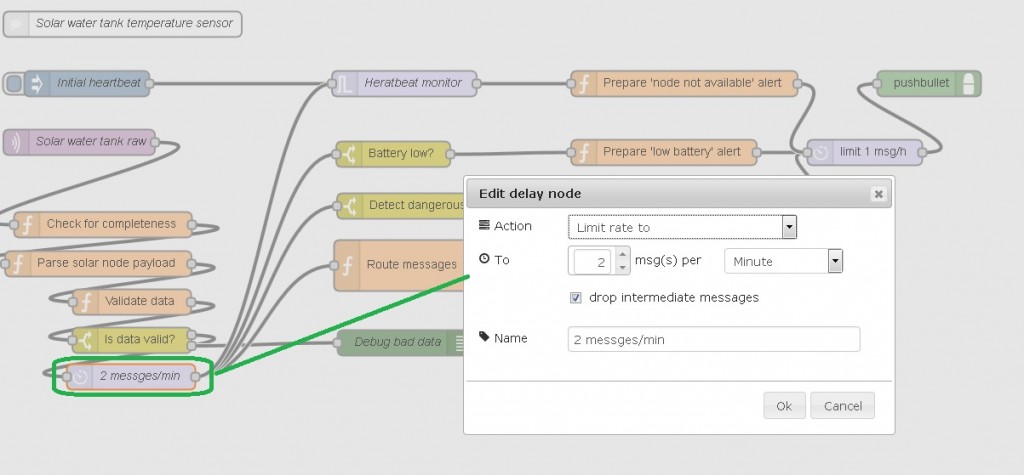
Accuracy
This particular node does not perform accuracy validation, I use that sort of validation in GPS location tracking node.
Timeliness
Timeliness is ensured by providing a MQTT time stamp topic, so that the consuming process’ business logic can decide if the data is good or bad:
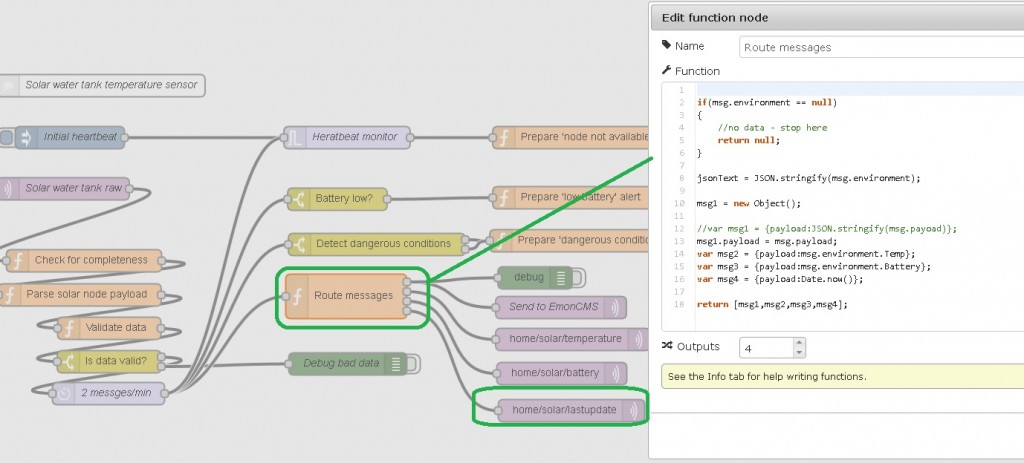
Availability
Availability is tracked by a ‘heartbeat monitor’ mechanism; Failing to receive a heartbeat (valid data) within a pre-set time interval results in a notification being sent to me:
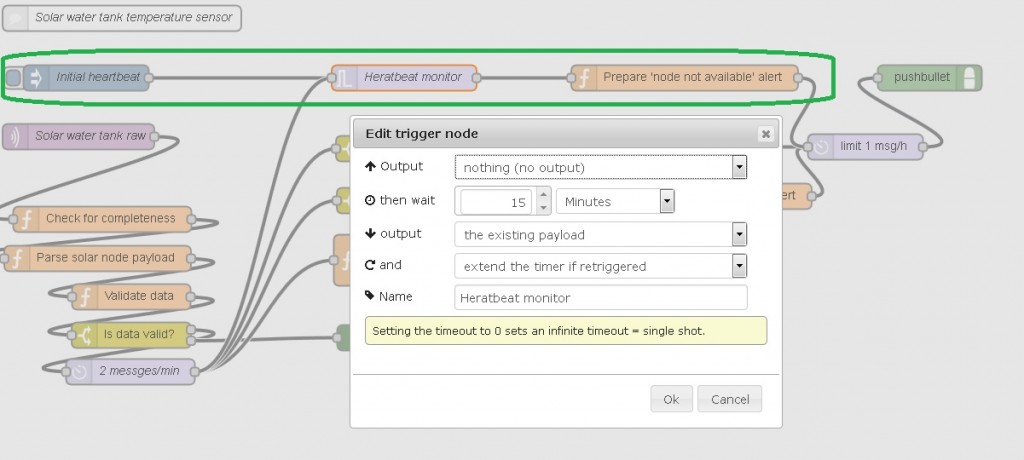
The above workflow is available to try out:
Monitor DQ exceptions
In an ideal world, you’d log data quality exceptions and analyze that information to adjust the processes, however this is a small home automation system and I will limit this task to providing debug information only.
Conclusion
As a conclusion from this my effort, the quality of the data I collect for my home automation purposes has improved materially and my trust in it has increased. Well worth the effort.
Hi Martin, I’ve picked up some useful ideas from this blog, and plan to assess my own system DQ and build in some resilience.
Have you considered having an ‘external’ heartbeat to check that node-red hasn’t frozen?
I don’t know if such a service is available, but something similar to pingdom.com but instead of monitoring a website, it expects a response from node-red via http request/response, and if not, lets you know.
Paul
Hi Paul,
I do experience node-red crashes occasionally and solved that by modifying the startup script to run this:
#!/usr/bin/env bash
cd /home/pi/node-red
while true; do
node --max-old-space-size=128 red.js
/bin/sleep 2
done
With this modification, I ensure node-red is always up; I send myself a pushbullet notification every time node-red starts, so I am aware when the glitching happens.
Another scenrario would be lost internet connectivity, node red would still be running, but external heartbeat monitor would report it down.
Hi Martin,
it would be good to understand what’s causing your occasional crashes of Node-RED… it shouldn’t be doing that 🙂
Do you capture any logs?
Nick
Hi Nick,
These are rare indeed, could happen once or twice a week; I run my Pi in RO file system mode and only switch to RW for deployment; I have observed more frequent crashes immediately following a deployment, I just experimented now and after few successful deployments got:
3 Sep 11:17:30 - [red] Uncaught Exception: (/home/pi/node-red/nodes/core/io/10-mqtt.js:98:33) (/home/pi/node-red/nodes/core/io/lib/mqttConnectionPool.js:64:37) (/home/pi/node-red/nodes/core/io/lib/mqtt.js:137:28) 3 Sep 11:17:30 - TypeError: Cannot call method 'isConnected' of null
at Object.connections.(anonymous function).obj.publish (/home/pi/node-red/nodes/core/io/lib/mqttConnectionPool.js:50:36)
at MQTTOutNode.
at MQTTOutNode.emit (events.js:95:17)
at MQTTOutNode.Node.receive (/home/pi/node-red/red/nodes/Node.js:118:10)
at MQTTInNode.Node.send (/home/pi/node-red/red/nodes/Node.js:107:38)
at /home/pi/node-red/nodes/core/io/10-mqtt.js:52:26
at MQTTClient.
at MQTTClient.emit (events.js:117:20)
at Connection.
at Connection.emit (events.js:95:17)
I admit that I was lazy to further investigate the cause and took the easy way out by running node-red in a loop..
I was using node-red crashing as a potential example (my system recently went down due to a HDD error), either way, couldn’t we be sat confident that everything was OK because we have NOT received a push message, whilst in fact burglars had switched the power off to our home, nicked the Rasp Pi, and burnt our home to the ground to get rid of fingerprints (probably a bit extreme!! but I’m sure you will follow my thoughts..)
Paul
I see your point, it is fairly easy to implement this with external bot checking on your Pi and emailing you upon lack of connectivity. I just set it up for my system and will blog the details sometime soon.