
Here is a fun project to try out: a Siri-like voice talk with your Raspberry Pi, its a lovely way to attract youngsters and keep them entertained for a while. I use three components for the project, code is mainly scrapped out from various Internet sources
- A speech-to-text component that will do the voice recognition
- Some “brains” to analyze the so captured text
- A text to speech component that will speak out the result from component 2
The hardware required is a Raspberry Pi with Internet connectivity and a USB microphone. Pi is running the 2012-12-16-wheezy-raspbian image; I don’t have a USB microphone, but I have a USB webcam (Logitech V-UAV35) with in-built microphone, so that worked out fine without any driver installation.
Speech recognition for Raspberry Pi can be done in number of ways, but I thought the most elegant would be to use Google’s voice recognition functions. I used this bash script to get that part done (source):
#!/bin/bash arecord -D "plughw:1,0" -q -f cd -t wav | ffmpeg -loglevel panic -y -i - -ar 16000 -acodec flac file.flac > /dev/null 2>&1 wget -q -U "Mozilla/5.0" --post-file file.flac --header "Content-Type: audio/x-flac; rate=16000" -O - "http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium" | cut -d\" -f12 >stt.txt cat stt.txt rm file.flac > /dev/null 2>&1
..and then set it to executable:
chmod +x stt.sh
You may need to install ffmpeg
sudo apt-get install ffmpeg
So what this does is to record to a flac file from the USB microphone until you press Ctrl+C and then passes that file to Google for analysis, which in turn returns the recognized text. Lets give it a try:
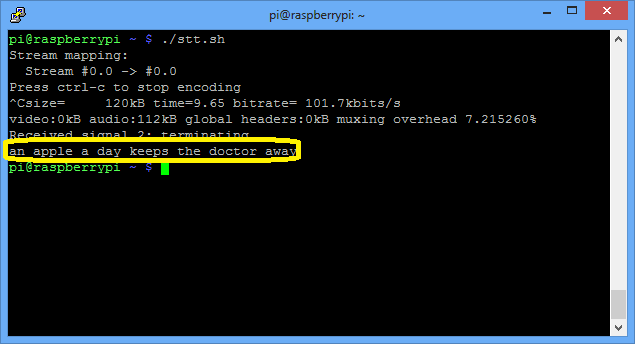
It work pretty good even with my bad accent. The output is saved to stt.txt file.
Now onto the “brains” section, this is with no doubt a task for Wolfram Aplha. I used Python to interface with it, there is already a library to use. It is pretty easy to install, just follow the instructions in the link. I had to get an API key, which is a 2 minute task and gives you 2000 queries a month.
#!/usr/bin/python
import wolframalpha
import sys
#Get a free API key here http://products.wolframalpha.com/api/
#I may disable this key if I see lots of abuse
app_id='Q59EW4-7K8AHE858R'
client = wolframalpha.Client(app_id)
query = ' '.join(sys.argv[1:])
res = client.query(query)
if len(res.pods) > 0:
texts = ""
pod = res.pods[1]
if pod.text:
texts = pod.text
else:
texts = "I have no answer for that"
print texts
else:
print "I am not sure"
.. and lets try it out with the questions that keep me up at night:
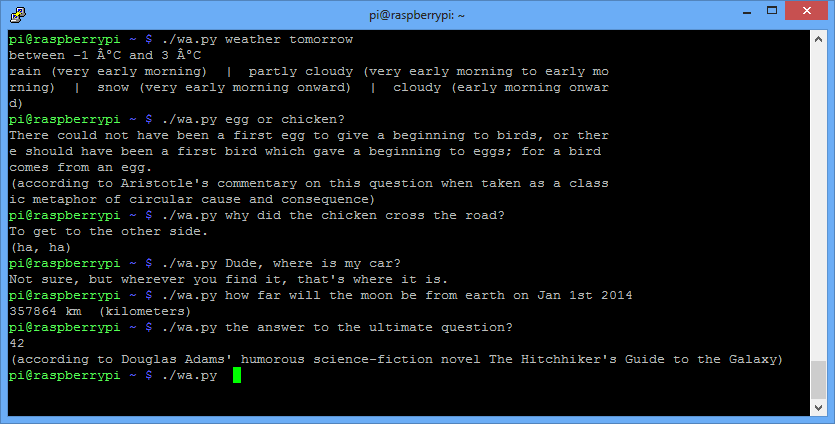
yep, brains are there. Now to the last part: speaking that answer out. Sure enough, we use Google’s speech services again (source)
#!/bin/bash
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols "http://translate.google.com/translate_tts?tl=en&q=$*"; }
say $*
..you may need to “sudo apt-get install mplayer” first..
It sounds pretty cool indeed.
So finally a small script to put these to work together:
#!/bin/bash echo Please speak now and press Ctrl+C when done ./stt.sh ./tts.sh $(./wa.py $(cat stt.txt))
So overall a fun project, maybe with some potential to use in home automation..
I’ve been experimenting with Google Voice recognition too, but found problems using a USB mic with the Pi (too quiet, even with alsamixer turned right up). The same mic works fine on Windows, which led me to discover some Google results that suggest recording audio via USB isn’t great on Linux. Did you have any problems in this area, and if so, how did you overcome them?
I have to speak somewhat loud for this to work, but just high voice, not shout at it. I use a webcam’s mic, maybe I am just lucky that it is sensitive enough. I just put alsamixer to max and nothing else.
Hi – i find the Logitec webcam’s with integrated mic work real nice. I have tried other USB mic’s & had similiar problems (too quiet, distorted & unsupported audio rates)
Never mind the kids; I’m enjoying making the computer shout stuff at me!
Hey now — this is fantastic! What a brilliant way to integrate all those services! I’m bookmarking this for dissection later.
I have read all your post.
I am having a problem at the first step only.Please help me.
when i paste the first binbash,i get the following error:
pi@raspberrypi ~ $ #!/bin/bash
pi@raspberrypi ~ $ arecord -D “plughw:1,0” -q -f cd -t wav | ffmpeg -y -i – -ar 16000 -acodec flac file.flac
ALSA lib pcm_hw.c:1401:(_snd_pcm_hw_open) Invalid value for card
arecord: main:682: audio open error: No such file or directory
ffmpeg version 0.8.6-6:0.8.6-1+rpi1, Copyright (c) 2000-2013 the Libav developer s
built on Mar 31 2013 13:58:10 with gcc 4.6.3
*** THIS PROGRAM IS DEPRECATED ***
This program is only provided for compatibility and will be removed in a future release. Please use avconv instead.
pipe:: Invalid data found when processing input
pi@raspberrypi ~ $ wget -q -U “Mozilla/5.0” –post-file file.flac –header “Cont ent-Type: audio/x-flac; rate=16000” -O – “http://www.google.com/speech-api/v1/re cognize?lang=en-us&client=chromium” | cut -d\” -f12
pi@raspberrypi ~ $ rm file.flac
rm: cannot remove `file.flac’: No such file or directory
can you try to run “sudo usermod -a -G audio pi”? You will have to log out/log in again for this to take effect
I tried the google speech service but didnt work. I put below code in speech.sh file, hardcoded it to say ‘Hello’
#!/bin/bash
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols “http://translate.google.com/translate_tts?tl=en&q=hello”; }
say $*
When i put url – http://translate.google.com/translate_tts?tl=en&q=hello in my chrome browser it says out hello but not when i run speech.sh
I have installed mplayer and was able to play few mp3 file too. Please help
can you use a microphone from the audio port
No, it is audio out only
i have compiled everything, but i keep getting the error:
mplayer: could not connect to socket
mplayer: No such file or directory
then the speaker says:
“I am not sure”
i have trawled the internet for these error messages but i just cant find the solution, any ideas?
I also had the same problem with mplayer. I could play wav files but could not get google translate to play or mp3’s to play. So I just swapped out the call to mplayer with mpg321:
#!/bin/bash
say() { local IFS=+;/usr/bin/mpg321 -q “http://translate.google.com/translate_tts?tl=en&q=$*”; }
say $*
I know it doesn’t solve mplayer, but it is a work around to get you going.
Thanks for sharing
so… the stt.sh file simply didn’t work for me, I HAVE installed ffmpeg, I’m using the newest version of raspbian, I’ve followed all instructions, and… the stt.sh file simply doesn’t work for me
Hey! I keep getting that “bad fd number”-error in stt.sh, can anyone help me with that?
Hello, I am having issues recording in with the speech to text. I am using a logitech C905 webcam with built in mic.
When I run speech2text or the entire program I recieve ^Ccut: invalid byte or field list
Try ‘cut –help’ for more information.
I assume this means nothing is being picked up from the microphone.
I am thinking that something is not configured properly in alsa, when I try to run arecord, I receive the following message
arecord: main:682: audio open error: No such file or directory
I have verified that my user is a member of the audio group, I don’t really know what else to try before I buy a new webcame or usb mic. I am currently running facial recognition through opencv with the cam, and it’s working wonderfully, so I really don’t want to fiddle with a different camera if I can avoid it, and the arecord error makes me think it must be a configuration issue?
Pingback: Cubieboard Voice Recognition | cubieboard